服務熱線
檔案智能分類是借助人工智能技術,讓系統自動完成檔案的類別劃分與歸類整理,替代傳統的人工分類模式。其核心是通過算法學習檔案的特征規律,實現“輸入檔案內容,自動匹配類別”的智能化過程。這一技術不僅能提升分類效率,還能減少人工主觀判斷導致的偏差,為檔案管理的標準化、精細化提供支撐。實現檔案智能分類需構建“數據基礎-技術模型-流程機制”三位一體的體系,確保分類結果既符合業務規則,又適應動態變化的管理需求。?
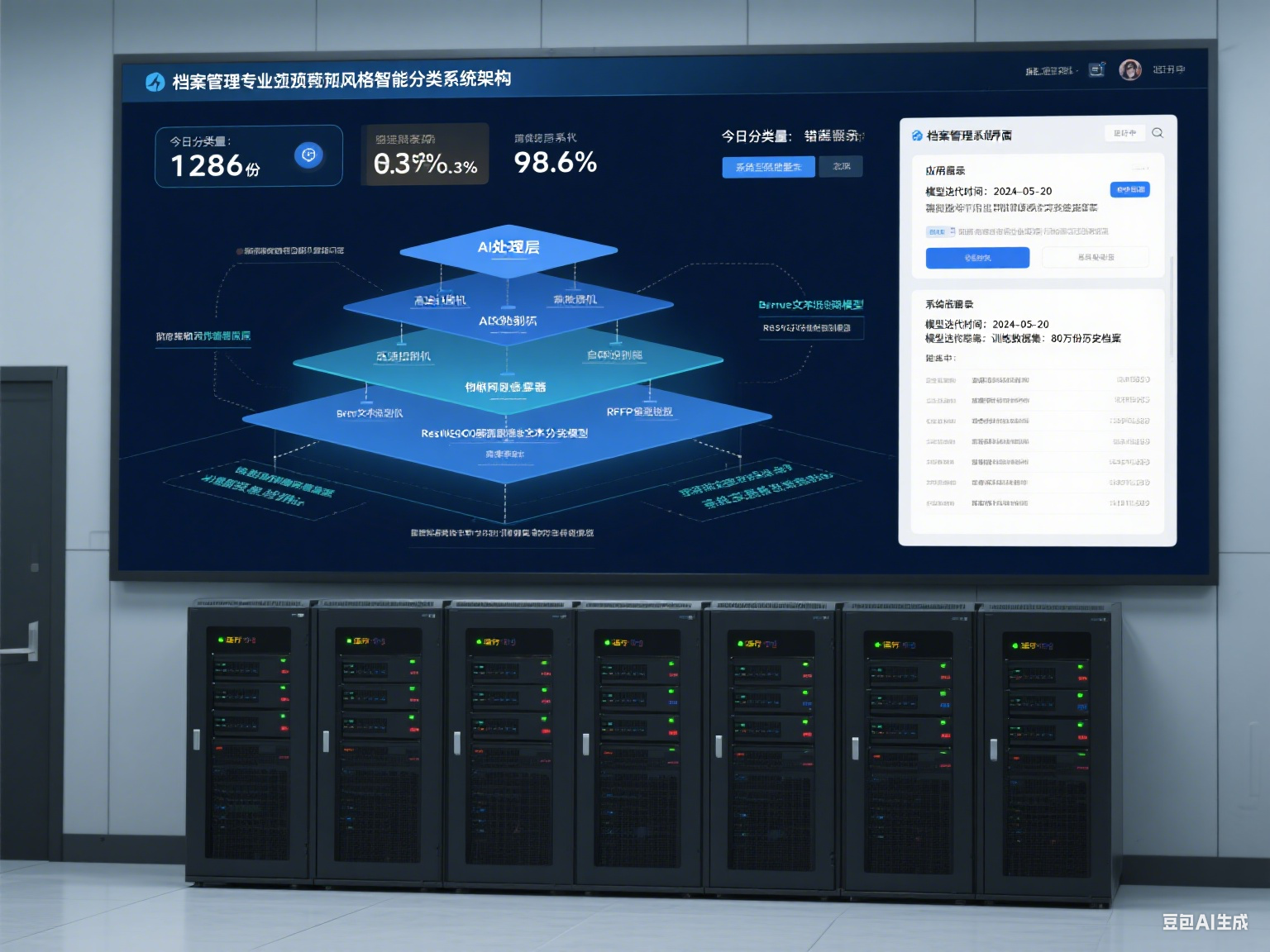
一、基礎條件:數據準備與分類體系構建?
智能分類的實現需以規范的數據基礎和明確的分類標準為前提,這是算法學習與分類決策的“原材料”和“參照物”。?
數據預處理是基礎工程。需將待分類的檔案轉化為算法可識別的格式:文本類檔案(如合同、報告)通過OCR技術提取文字內容,去除冗余信息(如頁眉頁腳、重復段落);圖像類檔案(如圖紙、照片)通過特征提取技術(如邊緣檢測、關鍵詞識別)轉化為結構化描述;聲像類檔案(如錄音、視頻)通過語音轉文字、畫面幀分析提取關鍵信息。預處理后的檔案數據需統一存儲于結構化數據庫,為模型訓練提供高質量樣本。?
分類體系需標準化定義。需明確“層級分類框架”,如按“全宗-類別-子項”三級劃分,或按“業務領域-檔案類型-時間”多維劃分。每個類別需設定明確的“特征標簽”,如“合同類”檔案的標簽可包括“甲方乙方、標的金額、簽訂日期、履行期限”等;“會議類”檔案的標簽可包括“會議名稱、參會人員、決議事項”等。標簽需具有互斥性和窮盡性,避免分類邊界模糊(如某一檔案同時符合多個類別的核心特征),確保算法能精準匹配。?
二、核心技術:算法模型與學習機制?
智能分類的技術核心是“算法模型”,通過機器學習從歷史分類數據中總結規律,形成自動分類的“決策邏輯”。不同類型的檔案需適配不同的算法,確保分類精度。?
文本類檔案以自然語言處理為核心。可采用“樸素貝葉斯”“支持向量機”等傳統算法,通過關鍵詞頻次、語義關聯分析判斷類別。對復雜文本(如多主題報告),需引入“深度學習模型”(如BERT、LSTM),理解上下文語義,識別核心主題。例如,通過分析“合同”與“協議”的語義差異(如合同更強調法律約束,協議更側重合作意向),實現細分品類的精準分類。?
非文本類檔案依賴特征匹配算法。圖像類檔案可通過“卷積神經網絡”提取視覺特征(如工程圖紙的線條特征、印章的形狀特征),與預設類別特征庫比對;聲像類檔案通過“音頻特征提取”(如語速、關鍵詞)和“視頻幀分析”(如場景、人物)生成分類依據。非文本類算法需結合“文本輔助信息”(如檔案標題、說明文字)提升精度,形成“視覺/聽覺特征+文本特征”的多維度判斷。?
模型訓練需持續迭代優化。初期用“已人工分類的檔案樣本”訓練模型,通過“監督學習”讓算法掌握分類規則;模型上線后,將人工修正的錯誤分類案例(如模型誤判的檔案)作為新樣本,通過“增量學習”更新模型參數,逐步提升分類準確率。對新增類別(如業務擴展產生的新型檔案),需補充該類別樣本進行專項訓練,避免模型對新類別“識別盲區”。?
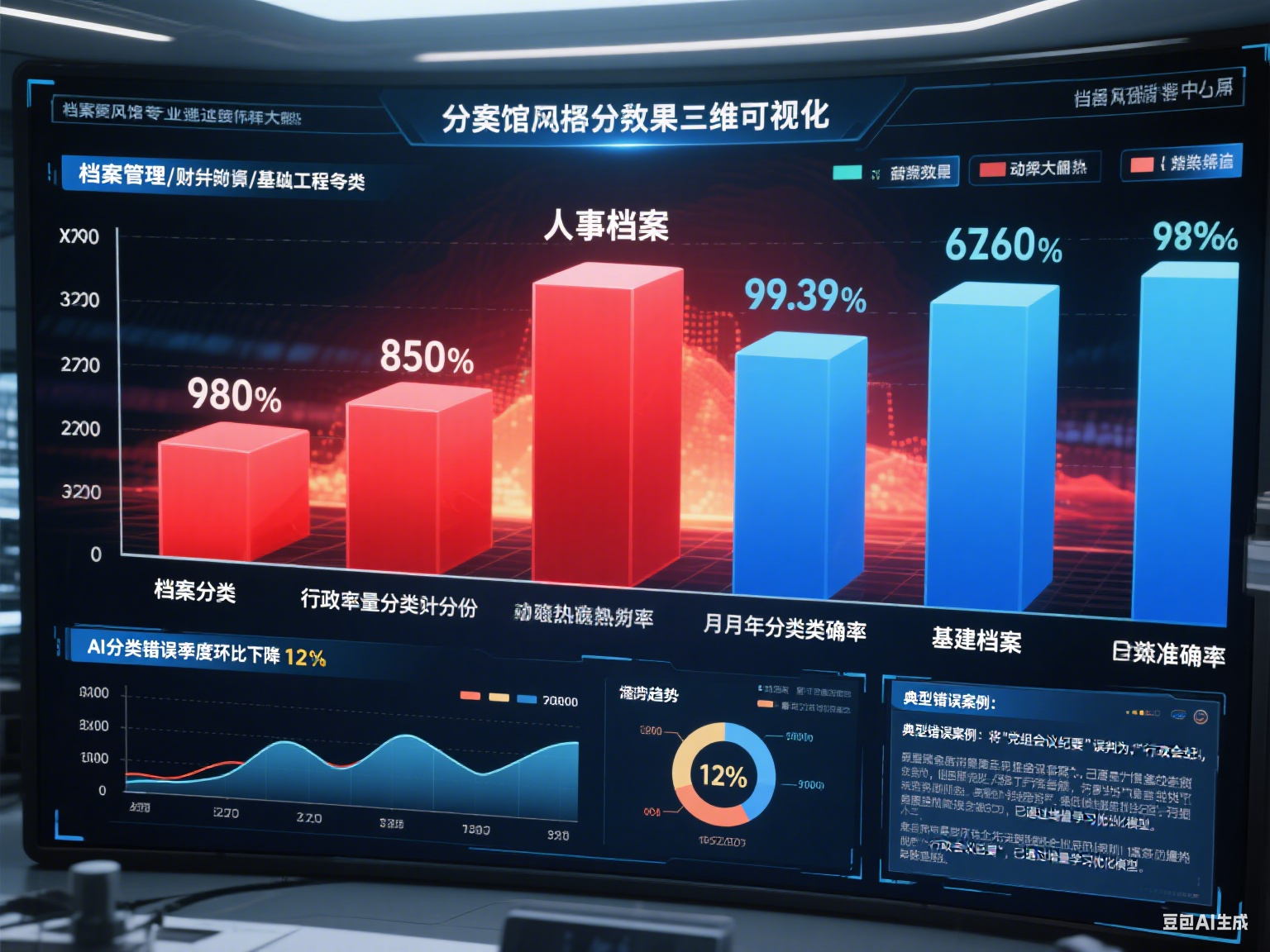
三、實現流程:從訓練到應用的閉環?
智能分類的落地需遵循“樣本訓練-模型測試-上線應用-反饋優化”的流程,確保技術與業務需求無縫銜接。?
樣本訓練階段需“足量且均衡”。需選取覆蓋所有類別的歷史檔案作為訓練樣本,樣本數量需滿足模型學習需求(通常每個類別樣本量不低于100條),且各類別樣本比例需均衡(避免某一類別樣本占比過高導致模型偏向性)。訓練過程中需劃分“訓練集”(70%樣本)和“驗證集”(30%樣本),通過驗證集測試模型分類精度,若精度低于預設閾值(如85%),需增加樣本量或調整算法參數。?
模型測試需模擬真實場景。選取未參與訓練的“測試檔案”(數量為訓練樣本的20%),用模型自動分類后與人工分類結果比對,統計“準確率”(正確分類的檔案占比)、“召回率”(某類別檔案被正確識別的比例)、“F1值”(綜合評估指標)。重點關注“易混淆類別”的分類效果(如“請示”與“報告”的區分),對錯誤案例分析原因(如特征標簽不明確、算法未捕捉關鍵差異),針對性優化。?
上線應用需“人機協同”過渡。初期采用“模型預分類+人工審核”模式:模型自動生成分類建議,由檔案人員確認或修正,修正結果同步反饋至模型進行迭代。隨模型精度提升(如準確率達95%以上),可逐步減少人工干預,僅對“低置信度分類”(如模型判斷某檔案屬于A類的概率為60%)進行人工審核。同時,系統需記錄分類日志(如分類時間、模型版本、人工修正記錄),為質量追溯和模型優化提供依據。?
四、關鍵要點:保障分類效果的核心策略?
智能分類的有效性不僅依賴技術,還需通過“規則約束”“動態適配”“權限管控”等策略,確保分類結果符合業務規范和管理需求。?
規則引擎需補充算法不足。對有明確業務規則的分類場景(如“涉密檔案必須歸入保密類別”“永久保管檔案單獨分類”),需在模型外設置“規則引擎”,強制優先執行業務規則,避免算法因數據偏差導致違規分類。規則引擎需可配置,支持業務人員根據管理需求調整規則(如新增“疫情防控專項檔案”分類規則),增強系統靈活性。?
動態適配業務變化。當檔案類型、分類標準發生調整(如機構改革導致業務領域變動),需通過“快速再訓練”更新模型:新增對應類別的樣本數據,重新訓練模型參數;調整分類體系標簽,確保模型輸出與新體系匹配。同時,系統需支持“批量重分類”,對歷史檔案按新規則重新分類,避免新舊分類體系混雜。?
權限管控確保分類安全。不同類別檔案的分類權限需差異化設置:普通類別可由模型自動分類;涉密、敏感類別需疊加人工審核(如三級審核機制),且分類操作需記錄權限日志,防止越權分類或惡意篡改。系統還需對分類結果進行“合規性校驗”(如檢查涉密檔案是否標注密級),不符合規范的分類需退回整改,保障檔案管理的嚴肅性。?
檔案智能分類的實現,是技術與管理的結合:通過算法提升效率,通過規則保障合規,通過迭代適應變化。其最終目標不是完全替代人工,而是構建“機器擅長分類、人類負責決策”的協同模式,讓檔案管理從繁瑣的重復勞動中解放出來,聚焦更具價值的利用與服務工作,為檔案資源的深度開發奠定基礎。?


